如何在MCU上實現(xiàn)AIoT?瀏覽數(shù):0
物聯(lián)網(wǎng)設備越來越多地采用人工智能技術來創(chuàng)建智能“物聯(lián)網(wǎng)”(AIoT),這使很多應用從中受益。同時也為MCU(微控制器)開辟了新的市場,賦能越來越多的新應用和新用例,以利用簡單的 MCU搭配AI加速來促進智能控制。這些AI加持的MCU融合了DSP計算和機器學習(ML)推理能力,適合關鍵字識別、傳感器融合、振動分析和語音識別等多種應用。更高性能的MCU還可以支持更復雜的視覺和成像應用,例如人臉識別、指紋分析和自主機器人等。
本文圍繞AI技術、如何通過MCU實現(xiàn)AIoT以及邊緣AI等方面進行了系統(tǒng)的分析。推薦給大家。
物聯(lián)網(wǎng)設備越來越多地采用人工智能技術來創(chuàng)建智能“物聯(lián)網(wǎng)”(AIoT),這使很多應用從中受益。這些智能物聯(lián)網(wǎng)設備從數(shù)據(jù)中學習,并在無需人工干預的情況下做出自主決策,從而使產(chǎn)品與其環(huán)境之間實現(xiàn)更合乎邏輯、更接近人類的交互。
AI和物聯(lián)網(wǎng)的結合為MCU(微控制器)開辟了新的市場,賦能越來越多的新應用和新用例,以利用簡單的 MCU搭配AI加速來促進智能控制。這些AI加持的MCU融合了DSP計算和機器學習(ML)推理能力,適合關鍵字識別、傳感器融合、振動分析和語音識別等多種應用。更高性能的MCU還可以支持更復雜的視覺和成像應用,例如人臉識別、指紋分析和自主機器人等。
以下是為物聯(lián)網(wǎng)設備帶來AI功能的部分使能技術:
-
機器學習 (ML):機器學習算法根據(jù)代表性數(shù)據(jù)構建模型,使設備能夠在無需人工干預的情況下自動識別模式。ML供應商提供算法、API 和工具以構建訓練模型,然后將模型植入到嵌入式系統(tǒng)中。輸入新的數(shù)據(jù)后,這些嵌入式系統(tǒng)就可以利用預先訓練的模型進行推理或預測,這類應用示例包括傳感器融合、關鍵字識別、預測性維護和分類等。
-
深度學習(DL):深度學習是機器學習的一種,它使用多層神經(jīng)網(wǎng)絡從復雜的輸入數(shù)據(jù)中逐步提取更高級別的特征和模式,從而訓練系統(tǒng)。深度學習可以適應非常龐大、多樣化和復雜的輸入數(shù)據(jù),并讓系統(tǒng)不斷迭代學習,逐步改善輸出結果。其應用示例包括圖像處理、客服機器人和人臉識別等。
-
自然語言處理 (NLP):NLP是人工智能的一個分支,可以實現(xiàn)系統(tǒng)與人類之間用自然語言進行交互。NLP幫助系統(tǒng)理解和解釋人類語言(文本或語音),并基于此做出決策。其應用示例包括語音識別系統(tǒng)、機器翻譯和預測性打字等。
-
計算機視覺:機器/計算機視覺是人工智能的一個領域,它訓練機器收集、解釋并理解圖像數(shù)據(jù),并根據(jù)這些數(shù)據(jù)采取行動。機器通過攝像頭收集數(shù)字圖像/視頻,使用深度學習模型和圖像分析工具準確識別和分類對象,并根據(jù)它們所“看到”的采取相應的行動。其應用示例包括制造裝配線上的故障檢測、醫(yī)療診斷、零售店的人臉識別和無人駕駛汽車測試等。
過去,AI屬于MPU和GPU的應用范疇,它們擁有強大的CPU內(nèi)核、大內(nèi)存資源和進行AI分析的云連接。但近年來,隨著邊緣智能程度的不斷提高,我們開始看到MCU被用于嵌入式AIoT應用中。向邊緣轉移是基于延遲和成本的考慮,同時還可以讓計算處理更接近數(shù)據(jù)源。基于MCU的物聯(lián)網(wǎng)設備具有AI功能可以實現(xiàn)實時決策和更快的事件響應,而且還有更多其它優(yōu)勢,諸如更低的帶寬要求、更低的功耗、更低的延遲、更低的成本和更高的安全性。有了更高計算能力的新型MCU加持,再加上更適合資源受限MCU的神經(jīng)網(wǎng)絡 (NN) 框架,AIoT得以實現(xiàn)。
神經(jīng)網(wǎng)絡是很多節(jié)點的集合,這些節(jié)點按層排列。每一層都接收來自前一層的輸入,并根據(jù)輸入的權重和偏置總和進行計算,以生成輸出。輸出沿其所有傳出連接傳遞到下一層。在訓練過程中,訓練數(shù)據(jù)被饋入網(wǎng)絡的第一層或輸入層,每一層的輸出再傳遞到下一層。最后一層或輸出層生成模型的預測,將其與已知的預期值進行比較從而評估模型的誤差。訓練的過程需要在每次迭代中使用稱為“反向傳播”的過程完善步驟,或調(diào)整網(wǎng)絡每一層的權重和偏置,直到網(wǎng)絡輸出與預期值密切相關。換句話說,網(wǎng)絡從輸入數(shù)據(jù)集中迭代“學習”,并逐步提高輸出預測的準確性。
神經(jīng)網(wǎng)絡的訓練需要極高的計算性能和內(nèi)存,通常在云端進行。訓練之后,這個預訓練的神經(jīng)網(wǎng)絡(NN)模型被嵌入到MCU中,即可作為推理引擎對新傳入數(shù)據(jù)進行處理。
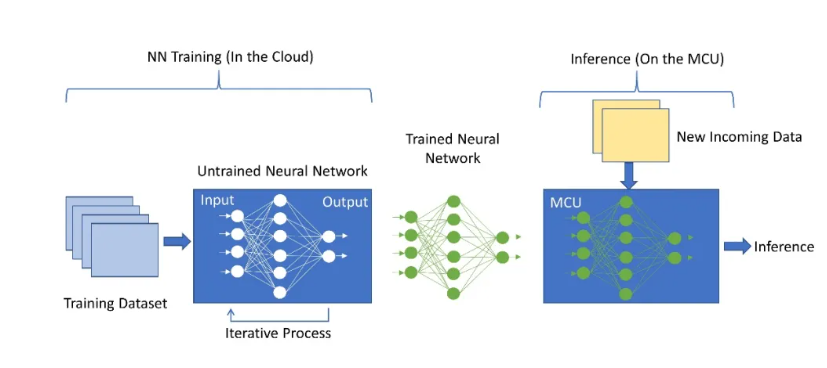
圖1: 神經(jīng)網(wǎng)絡的訓練與推理
這種推理生成所需要的計算性能比訓練模型要低很多,在MCU上即可實現(xiàn)。這種預訓練的神經(jīng)網(wǎng)絡模型權重是固定的,可以保存在閃存中,從而減少所需的SRAM數(shù)量,使其適用于更多資源受限的MCU。
MCU上的AIoT實現(xiàn)包含多個步驟。最常見的實現(xiàn)方法是使用現(xiàn)有的神經(jīng)網(wǎng)絡 (NN) 框架模型之一,例如Caffe或Tensorflow Lite,它們適用于基于MCU的終端設備解決方案。用于機器學習的NN模型訓練可由AI專業(yè)人員使用 AI供應商提供的工具在云端完成。NN模型優(yōu)化和MCU集成可以使用AI供應商和MCU制造商提供的工具進行。推理則在MCU上采用預訓練的NN模型完成。
上述過程的第一步可以完全離線完成,涉及從終端設備或應用捕獲大量數(shù)據(jù),并用于訓練NN模型。模型的拓撲結構由AI開發(fā)人員定義,以充分利用現(xiàn)有數(shù)據(jù)并提供應用要求的輸出。NN模型的訓練是通過將數(shù)據(jù)集迭代傳遞給模型來完成的,目的是不斷最小化模型輸出的誤差。NN框架提供的工具可以幫助完成這個過程。
在第二步中,針對特定功能(如關鍵字識別或語音識別)進行了優(yōu)化的預訓練模型被轉換為適應MCU的格式。在這個過程中,首先利用AI轉換器工具將模型轉換為flat buffer文件,也可以選擇通過量化器來轉換,以減小尺寸并針對MCU優(yōu)化。然后,將該flat buffer文件轉換為C代碼,并作為運行時可執(zhí)行文件傳輸給目標MCU。
配備了預訓練嵌入式AI模型的MCU現(xiàn)在就可以部署在終端設備中了。當新數(shù)據(jù)導入時,它在模型中運行,并根據(jù)訓練生成推理。當新的數(shù)據(jù)類別出現(xiàn)時,NN模型可以被發(fā)送回云端重新進行訓練,然后可以通過OTA(空中更新)固件升級將重新訓練后的新模型編入MCU。
構建基于MCU的AI解決方案有兩種不同的方式。為便于討論,本文我們假設目標MCU采用Arm Cortex-M內(nèi)核。
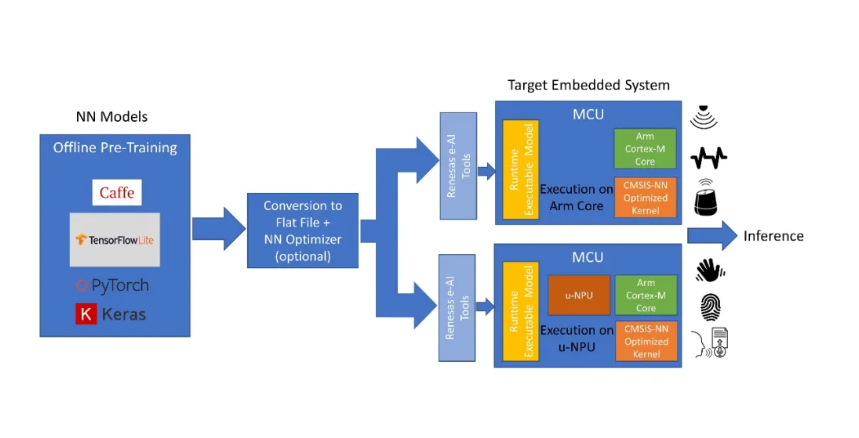
圖2:通過離線預訓練模型在MCU上實現(xiàn)AI。
在第一種方法中,轉換后的NN模型在Cortex-M CPU內(nèi)核上執(zhí)行,并通過CMSIS-NN庫加速。這是一種簡單的配置,無需任何額外的硬件加速,適用于較簡單的AI應用,例如關鍵字識別、振動分析和傳感器集合等。
另一種更復雜和更高性能的選擇則需要在MCU上配置NN加速器或微神經(jīng)處理單元(u-NPU)硬件。這些u-NPU 可在資源受限的IoT終端設備中加速機器學習,并且可能還支持壓縮以降低模型的功耗和大小。所支持的運算可以完全執(zhí)行大多數(shù)常見的NN網(wǎng)絡,以用于音頻處理、語音識別、圖像分類和對象檢測。u-NPU不支持的網(wǎng)絡可以回退到主CPU內(nèi)核,并由CMSIS-NN庫加速。在這種方法中,NN模型是在uNPU上執(zhí)行的。
在配置了MCU的設備中實現(xiàn)AI不只有這兩種方法。隨著MCU的性能不斷推向更高的水平,逐漸接近MPU的預期水準,我們將會看到完全的AI功能直接構建在MCU上,而且具有輕量級的學習算法和推理功能。
在資源受限的MCU上實現(xiàn)AI將在未來呈指數(shù)級增長。隨著MCU性能的不斷提升,MCU和MPU之間的界限越來越模糊,同時出現(xiàn)越來越多適用于資源受限設備的“瘦”神經(jīng)網(wǎng)絡模型,新的應用和用例將不斷浮現(xiàn)。
未來,隨著MCU性能的提高,我們將會看到除推理之外的輕量級學習算法直接在MCU上實現(xiàn)。這將為MCU制造商開辟新的市場與應用,并將成為其重要的投資領域。